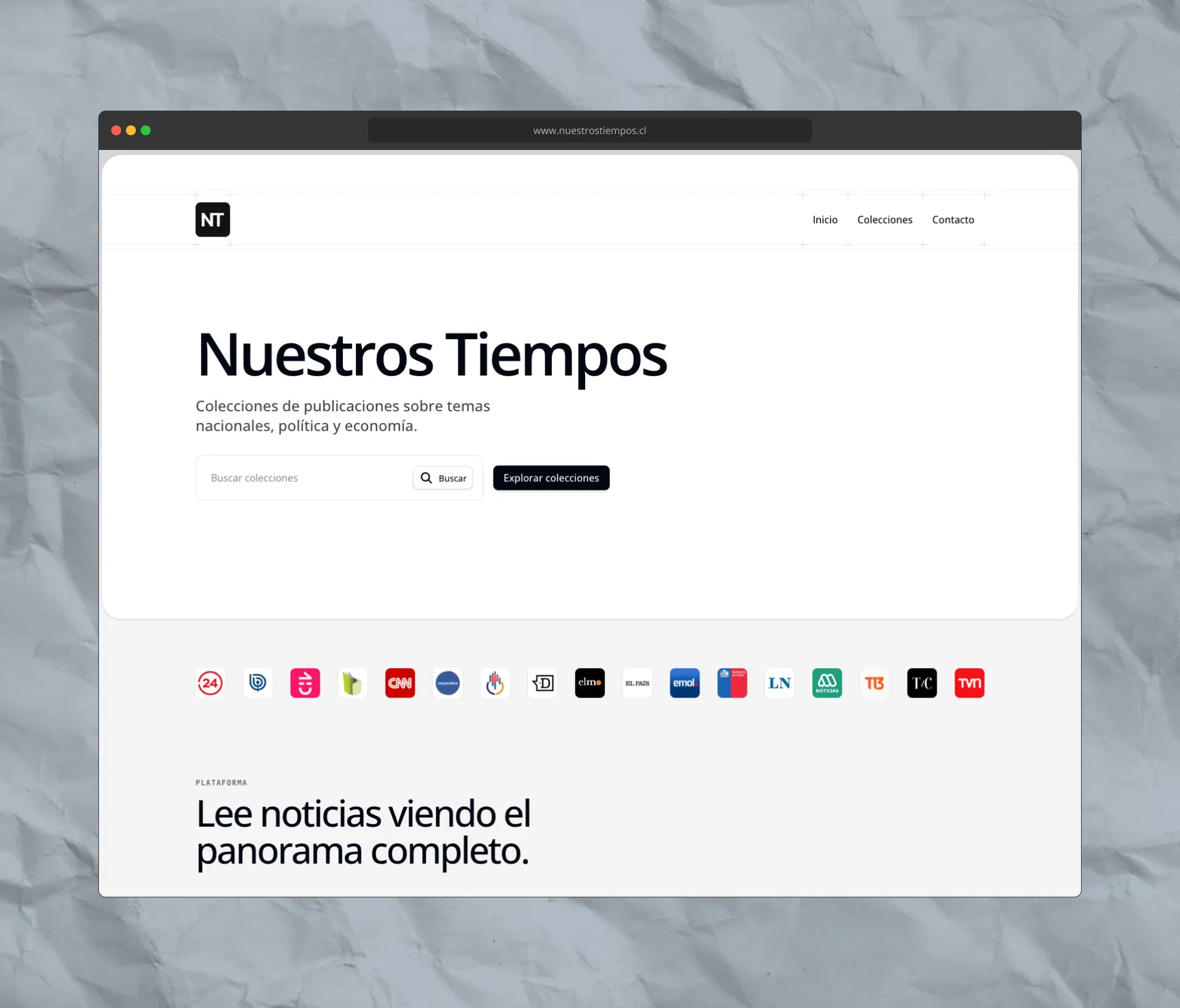
Case study - Nuestros Tiempos — Decoding Chile's News Complexity with AI
Nuestros Tiempos is an AI-powered news aggregation platform designed to analyze Chilean news narratives. It explores how unsupervised learning and vector embeddings can uncover patterns across thousands of news articles — automatically, without supervision.
www.nuestrostiempos.cl- Client
- Nuestros Tiempos
- Year
- Service
- Automation & AI
Tech Stack Highlights
- Laravel
- React
- LibSQL + SQLite
- Model2Vec
- UMAP + HDBSCAN
Overview
Nuestros Tiempos is an AI-powered news aggregation platform designed to analyze Chilean news narratives. Built by Codisans, it explores how unsupervised learning and vector embeddings can uncover patterns across thousands of news articles — automatically, without supervision, and on a server that costs just $4/month.
The Problem: Navigating Information & Misinformation
In today's information landscape, people are overwhelmed by volume and bias.
Chileans, like audiences everywhere, face an invisible problem: news fragmentation.
Each outlet presents partial narratives, making it hard to understand the complete picture.
Nuestros Tiempos tackles this by automatically identifying different narratives around the same news event, allowing users to explore multiple perspectives in one place — a key step toward reducing misinformation and polarization.
Objectives
- Develop a fully automated news clustering system to group semantically similar articles.
- Achieve high-quality clustering with zero supervision and minimal resources.
- Run the entire system on a tiny VPS for less than $4/month.
- Build a modern, responsive UX that presents AI insights clearly to users.
Vision
"Decoding Chile's News Complexity with AI"
Nuestros Tiempos represents Codisans' vision for applied AI: accessible, ethical, and efficient.
Rather than relying on large, expensive LLM pipelines, this project proves how traditional yet powerful ML techniques — when combined creatively — can deliver meaningful impact.
Machine Learning Models & Approach
All models run on CPU — no GPU dependency — showing that ML creativity > hardware power.
Why These Technologies?
- Model2Vec: lightweight, deterministic, and fast for static embeddings.
- UMAP: maintains semantic proximity in lower dimensions, critical for clarity.
- HDBSCAN: automatically detects cluster density — perfect for uneven, real-world data like news.
Together, these form an elegant, resource-efficient unsupervised NLP pipeline.
Pipeline
- Data Cleaning & Normalization – Text extracted from 16 major Chilean outlets (Emol, CNN Chile, Cooperativa, T13, etc.)
- Vectorization – Each article is converted into a 768-dimensional vector using a static model distilled from Google DeepMind's EmbeddingGemma with Model2vec.
- Dimensionality Reduction – Reduced using UMAP to reveal meaningful topological relationships.
- Clustering – Applied HDBSCAN to detect natural groupings without preset parameters.
- Filtering & Validation – Outliers removed, clusters refined.
- Collection Generation – Articles grouped into readable "collections" of narratives.
All data is stored in SQLite and LibSQL (for vectors), using native SQLite FTS5 for full-text search — no external search services needed.
Results
- 100% automated pipeline
- No manual labeling or supervision
- Human-readable, coherent clusters
- Native full-text search without extra services
- Deployed on a small VPS with a cost of $4/month
Challenges & Solutions
| Challenge | Codisans' Solution |
|---|---|
| Resource constraints | Smart use of static embeddings + UMAP + HDBSCAN on CPU |
| Cluster accuracy | Fine-tuned HDBSCAN parameters (min_samples, min_cluster_size) |
| Search relevance | Native SQLite FTS5 implementation for scalable local search |
| UX complexity | Minimalist UI with dynamic clustering visualization |
Conclusions & Learnings
- Even static embedding models can produce surprisingly strong results when combined thoughtfully.
- UMAP and HDBSCAN parameters significantly affect cluster quality — hyperparameter tuning is key.
- Clean input data dramatically improves unsupervised outcomes.
- Minimalist architectures can achieve maximum insight per dollar.
Nuestros Tiempos is a testament to Codisans' philosophy:
AI should be useful, understandable, and efficient — not just impressive.
What could we achieve with more resources?
- Better embeddings by using Sentence-transformers for contextual embeddings
- Transformer-based summaries per cluster
- Larger-scale reclustering
- Quality assurance via transformer-based QA models
This could elevate Nuestros Tiempos from a research project to a full-fledged media intelligence platform.